Résumé
Les modèles à variables latentes sont très utilisés par de larges communautés pour analyser des données complexes, hétérogènes et dépendantes. Ils permettent en particulier de modéliser des phénomènes partiellement observés, par exemple avec des structures sous-jacentes inconnues. Ces modèles sont très riches du point de vue de la modélisation, mais difficiles à calibrer. Des méthodes ont été développées pour réaliser l’estimation de paramètres par maximum de vraisemblance avec des garanties théoriques de convergence dans des cadres très limités. Des chercheurs de INRAE, de CentraleSupelec, de l’Université de Lille et de l’Université de Technologie de Compiègne ont proposé une nouvelle méthode de machine learning pour estimer les paramètres d’un modèle à variables latentes très général. Plus précisément, ils ont développé un algorithme du gradient stochastique pré-conditionné et ont établi des garanties de convergence. De plus, la méthode permet d’obtenir simultanément les estimateurs des paramètres par maximum de vraisemblance et des intervalles de confiance associés. Une extension au cas de paramètres de grande dimension est en cours. Du point de vue pratique, ce type de développement permettra d’inclure dans les modèles de prédiction phénotypiques, par exemple des modèles de culture ou d’écophysiologie des plantes, des variables descriptives de grande dimension, telles que des marqueurs génétiques ou des spectres proches infra rouges, et d’identifier les localisations influentes du génome ou du spectre, dans un objectif de sélection génétique.
Contexte et enjeux : Les modèles à variables latentes sont très utilisés par de larges communautés pour analyser des données complexes, hétérogènes et dépendantes. Ils permettent en particulier de modéliser des phénomènes partiellement observés, par exemple avec des structures sous-jacentes inconnues comme les modèles de Markov cachés, des modèles de mélange de populations, des modèles avec plusieurs sources de variabilités comme les modèles à effets mixtes. Ces modèles sont très riches du point de vue de la modélisation. En revanche leurs paramètres sont difficiles à calibrer lorsqu’on souhaite ajuster des jeux des données, du fait de l’aspect partiellement observé du phénomène modélisé. Des méthodes ont été développées pour réaliser cette estimation de paramètres par maximum de vraisemblance. Cependant, les garanties théoriques de convergence des méthodes proposées ne sont établies que dans des cadres très restreints, à savoir les modèles de la famille exponentielle. L’enjeu est de proposer une méthode d’estimation qui s’applique dans des cadres très généraux et dont on puisse établir les garanties théoriques de convergence sous des hypothèses peu contraignantes.
Résultats : Des chercheurs de INRAE, de CentraleSupelec, de l’Université de Lille et de l’Université de Technologie de Compiègne ont proposé une nouvelle méthode de machine learning pour estimer les paramètres d’un modèle à variables latentes très général. Plus précisément, ils ont développé un algorithme du gradient stochastique pré-conditionné et ont établi des garanties de convergence. De plus, la méthode permet d’obtenir simultanément les estimateurs des paramètres par maximum de vraisemblance et des intervalles de confiance associés. Elle est par ailleurs très générique et facile à implémenter. Elle a déjà été appliquée pour inférer les paramètres de modèles de croissance et de modèles graphiques à blocs latents. Des modèles plus complexes tels que des modèles joints de survie et de données longitudinales sont également considérés.
Perspectives : Des développements sont en cours pour considérer un cadre statistique en grande dimension : l’enjeu est de sélectionner les paramètres les plus pertinents, dans un objectif de parcimonie. Dans ce contexte, il convient de régulariser l’estimation via des méthodes pénalisées. L’algorithme de gradient stochastique pré-conditionné peut être étendue à ce cadre, ainsi que les garanties de convergence. Du point de vue pratique, ce type de développement permettra par exemple d’inclure dans les modèles de prédiction phénotypiques, par exemple des modèles de culture ou d’écophysiologie des plantes, des variables descriptives de grande dimension, par exemple des marqueurs génétiques ou des spectres proches infra rouges, et d’identifier les localisations influentes du génome ou du spectre, dans un objectif de sélection génétique.
Références bibliographiques :
C. Baey, M. Delattre, E. Kuhn, J.B. Leger, S. Lemler. Efficient preconditioned stochastic gradient descent for estimation in latent variable models. International Conference on Machine Learning, 2023.
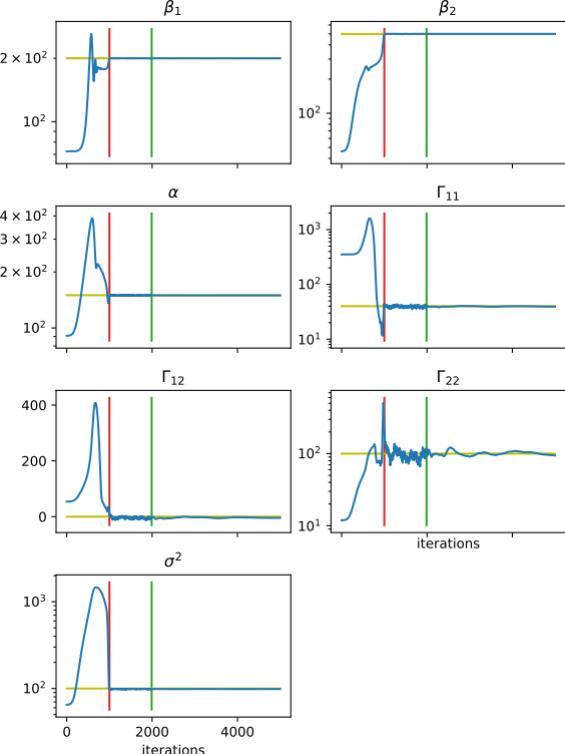
Evolution des estimations des sept paramètres d’un modèle de croissance au cours des itérations de l’algorithme en étude de simulation : en bleu les valeurs estimés par l’algorithme, en jaune la vraie valeur des paramètres, en rouge et vert, les fins des périodes de pré)chauffe et chauffe de l’algorithme. C. Baey, M. Delattre, E. Kuhn, J.B. Leger, S. Lemler.