Contexte scientifique et enjeux :
Cette thèse porte sur l’extraction et la structuration automatique de l’information contenue dans les articles scientifiques et s’inscrit dans un courant actif de travaux étudiant comment le développement et l’application d’outils d’analyse de littérature scientifique à grande échelle permet de faire progresser la démarche de recherche scientifique. Le fait en particulier de pouvoir trouver, extraire et recouper les données scientifiques présentes dans les articles constitue tout à la fois un levier d’accélération des recherches mais également un moyen d’améliorer leur reproductibilité. Cette thèse met plus particulièrement l’accent sur la reconnaissance d’entités et leur liaison à des bases de connaissances (entity linking/normalization), tâches qui constituent la pierre angulaire de ce type de travaux. L’objectif est de développer des méthodes robustes pour ces tâches dans des textes scientifiques. Le sujet soulève plusieurs verrous scientifiques importants. D’une part, les types d’entités d’intérêt varient fortement selon les disciplines, ce qui rend difficile la conception de méthodes génériques. D’autre part, la variabilité terminologique est très forte dans les textes scientifiques (ex : abréviations, synonymes, variations linguistiques), ce qui complique l’identification et la normalisation des entités. Enfin, le manque de données annotées dans les domaines spécialisés impose de concevoir des approches capables de fonctionner en contexte zero-shot ou few-shot, tout en restant robustes.
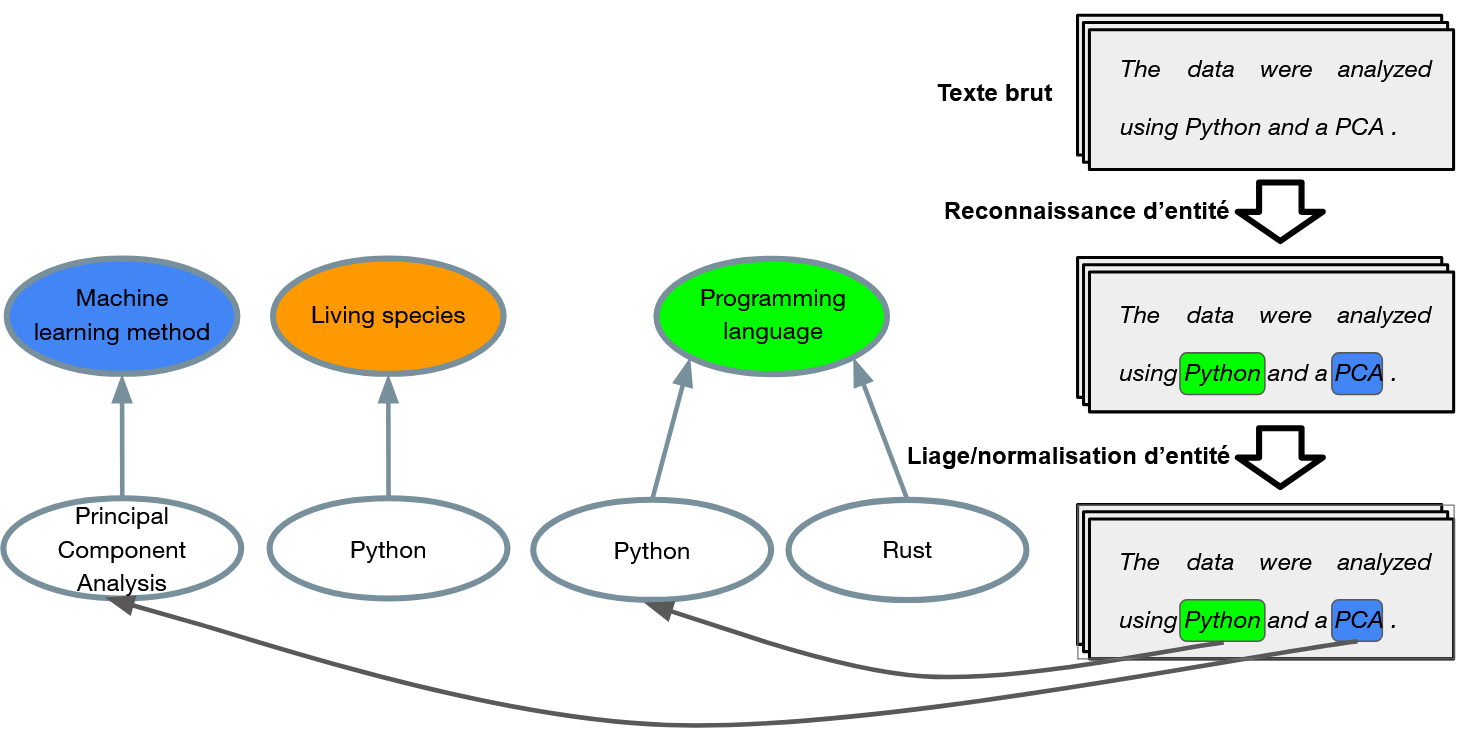
La thèse se déroulera dans le cadre du programme AIKO (France 2030), qui vise à développer des outils et infrastructures pour l’exploitation de la littérature scientifique à grande échelle, et dans une collaboration entre deux unités de recherche de l’université Paris-Saclay : le LASTI (CEA-List) et MaIAGE (centre INRAE de Jouy-en-Josas). Un co-financement (50%) est d’ores et déjà acquis via le programme AIKO. Le financement complémentaire est en cours de recherche via des appels à projets compétitifs. Dans ce contexte, l’identification d’un·e candidat·e fortement motivé·e constituera un atout important pour finaliser le montage.
Axes de recherche et méthodologie :
Ce projet de thèse s’inscrit dans une réflexion autour de l’articulation entre les différentes étapes de l’extraction d’information. La thèse pourra explorer différents niveaux de couplage entre ces tâches, avec l’objectif de dépasser les approches séquentielles classiques pour aborder des approches plus intégrées, où l’identification des mentions et leur normalisation sont étroitement liées. Le projet s’intéressera également à l’apport des modèles de langue génératifs (LLM), selon plusieurs perspectives complémentaires :
- leur utilisation pour la génération de données (data augmentation) dans des contextes zero-shot ou few-shot (Ye et al., 2024; Vollmers et al., 2025),
- leur rôle potentiel dans des architectures modulaires ou multi-agents, où différentes composantes du système se spécialisent sur des sous-tâches et interagissent entre elles (Wang et al., 2025),
- leur capacité à exploiter des formes riches de spécification des entités d’intérêt (ex : descriptions, exemples, guidelines) (Sainz et al., 2023).
Enfin, la thèse pourra explorer des approches hybrides combinant modèles encodeurs, tels que SciBERT (Beltagy et al., 2019), et modèles génératifs, avec une attention particulière portée aux compromis entre performance, généricité, coût computationnel et frugalité en données. L’objectif est de proposer des méthodes robustes et adaptables aux spécificités des textes scientifiques.
Les méthodes développées durant la thèse seront évaluées sur des jeux de données standards en reconnaissance et normalisation, tels que le NCBI Disease Corpus (Doğan et al., 2014) ou MedMentions (Mohan and Li, 2019).
Profil recherché :
Master/Grande École en informatique, avec spécialisation en TAL et/ou deep learning.
Bonnes compétences en programmation (Python, PyTorch/Tensorflow).
Une expérience en utilisation de LLMs, en fine-tuning de modèles de langue et/ou en extraction d’information serait appréciée.
Intérêt pour la recherche scientifique.
Candidature :
Envoyer CV, notes et lettre de motivation aux personnes mentionnées ci-dessous.
Bibliographie :